![]()
Normalisation calculation in fractionated LC-MS experiments
The goal of normalisation is to find a single scaling factor for each run in an experiment which compensates for different running conditions. Once these factors are calculated the normalised abundance is calculated from the raw abundance as:
a' = ks,f . a
where ks,f is the normalisation factor for the run which is fraction f of sample s.
In a fractionated experiment with S samples and F fractions there are S x F individual normalisation factors which need to be calculated.
| k1,1 | ⋯ | kS,1 |
| ⋮ | ⋱ | ⋮ |
| k1,F | ⋯ | kS,F |
If we express the individual normalisation factors as:
ks,f = kR(f),f . k's,f
where:
R(f) is a sample chosen to be the normalisation reference within fraction f.
k's,f is the factor required to normalise sample s to sample R(f).
These k's,f normalisation factors are calculated by the within fraction normalisation performed during the first part of the workflow where each fraction is analysed as an individual experiment. By normalising within fractions the between fraction normalisation problem is reduced from calculating S x F run normalisation factors to calculating F between fraction normalisation factors:
kR(1),1 … kR(F),F
To calculate the between fraction normalisation factors we make use of a general property of proteomics data which is that peptide/protein abundances tend to be log normally distributed and so the logs of the peptide/protein abundances tend to be normally distributed.
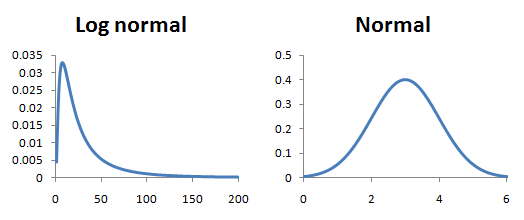
This means that the peptide abundances within each sample fraction should follow the same log normal distribution of the sample it was split from. As we have already normalised within fractions, all abundances within one fraction should follow a single log normal distribution. We can therefore normalise between fractions by finding the factor which will align these distributions.
The first step is to step is to convert the data to be normally distributed by taking the log of all non-zero within fraction normalised abundances:
a'' = log(k's,f . a)
For each fraction we first use a median based technique to reject outliers (excessively large or small abundances) and then calculate the mean of the remaining values to give a set of mean log normalised abundances
a''1 … a''F
Choosing the median mean log normalised (MMLNA) abundance as a target to normalise all fractions to, the individual between fraction normalisation factors are calculated as:
log(kR(f),f) = MMLNA - a''f
kR(f),f = 10MMLNA- a''f