




Principal Component Analysis
The Principal Component Analysis (PCA) in Progenesis QI for proteomics uses feature abundance levels across runs to determine the principle axes of abundance variation. Transforming and plotting the abundance data in principle component space allows us to separate the run samples according to abundance variation. This is useful in identifying run outliers.
Consider a simple experiment with 2 runs and 15 features on each run. We can plot the normalised abundances of the features in a 2-dimensional graph:
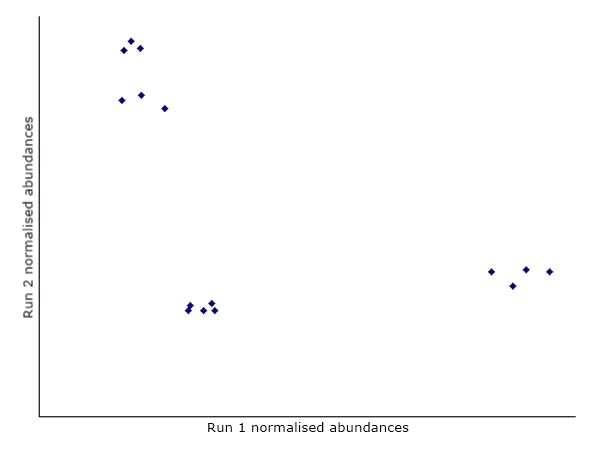
The first step in PCA is to draw a new axis representing the direction of maximum variation through the data. This is known as the first principal component.
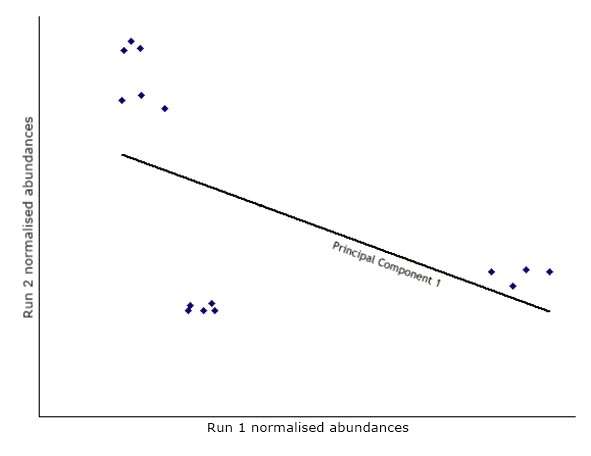
Next, another axis is added orthogonal to the first and positioned to represent the next highest variation through the data. This is the second principal component.
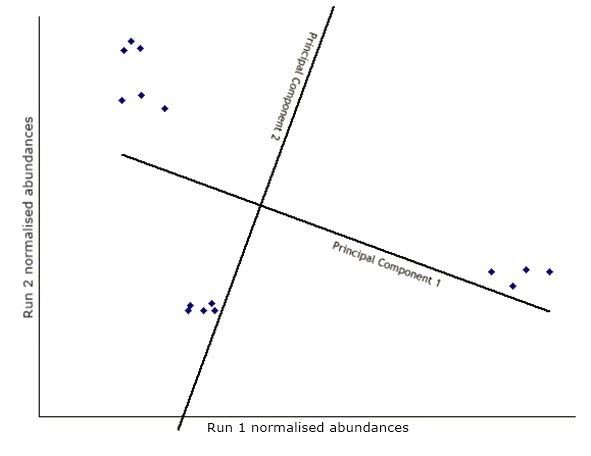
The data is then transformed (rotated) to view the points on the new axes.
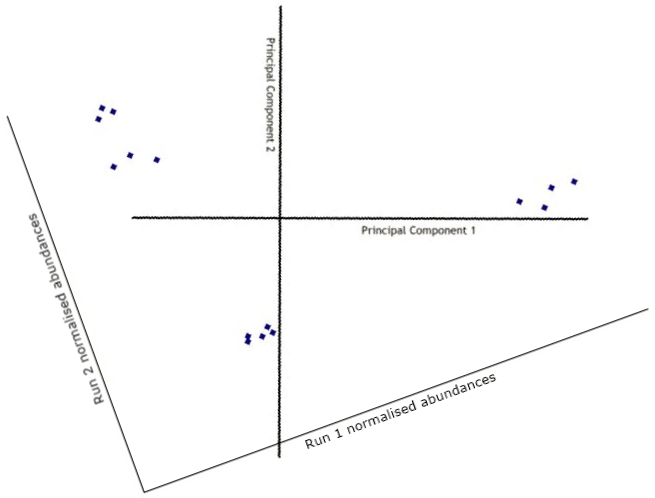
Obviously, with just 2 runs this is fairly pointless, as our brains can quite easily see the relationships between points in a two-dimensional space. However, with 3 runs the points are plotted in a 3-dimensional space, with 4 runs the points are plotted in a 4-dimensional space, and so on. In these cases, the process of adding more principal components continues, each one orthogonal to the previous one and each one accounting for less and less of the variance in the data set.
The result of this is that we can visualise features (and runs) in two- or three-dimensional space in such a way that features that are "close together" (i.e. not showing much variation) will appear together on the PCA plot and vice versa. By displaying runs as well as features on the same graph (called a biplot), we can help show which features are contributing to the difference between runs. This can then be used to determine which features are most important in distinguishing a particular run or group from the other runs or groups.
The PCA biplot
We can graph both transformed feature and run data on a biplot. The biplot contains a lot of information and can be helpful in interpreting relationships between experimental groups and features. Also, it can help to identify outlier runs, i.e. runs that have different properties to other runs in the same groups. In the biplot shown below, we can see that runs from each group (the coloured dots) are close to each other. However, the runs in group "Drug C" (the orange dots) are not as close as the runs in the other three groups. The features are also shown and appear to form two distinct groups.
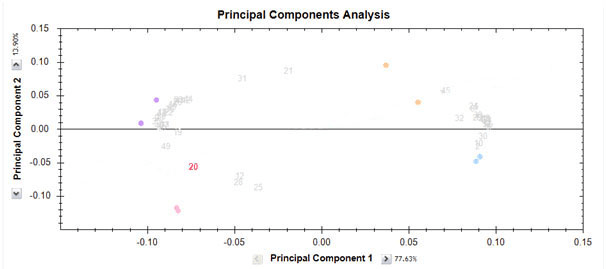
It is important to realise that if only those features that are significant (e.g. p-value < 0.05) are chosen, the PCA plot will be more likely to cluster runs according to their group. This is because a significant feature is one which exhibits differences between groups, and PCA captures differences between groups. Therefore, using significant features for the PCA will always see some sort of grouping. On the other hand, if we select all features and look at the biplot, we would still hope to see the groupings we expect. This can be a better indication of whether we have any run outliers. Finally, if all features are used in the biplot, it may be more useful to look at the second and third principle components. This is simply because PCA captures the variation that exists in the feature data and you have chosen all features. However, most of them will show no significant change (i.e. little variation) and so some other underlying source of variation may be captured in the first dimension.
Interpretation of feature position
The feature positions can be interpreted as follows. We can consider the feature number 20 in red on the biplot. Imagine a line going from the (0,0) position to the feature and also in the opposite direction. We can think of this as the feature axis. Like all axes, it has a positive side in the direction of the feature and a negative side in a direction away from the feature and on the other side of the (0,0) point.
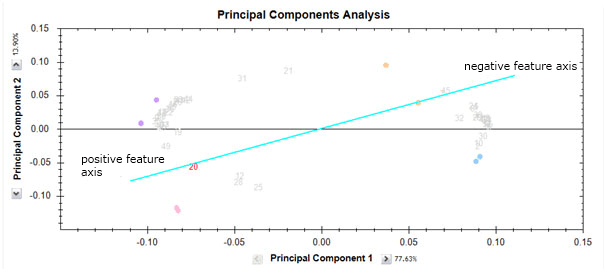
Now, runs on the positive side of the axis will have a high abundance value for the feature while runs on the negative side will have a low abundance value for this feature. The closer the run is to the axis, the more the influence of this feature for that run position. However, runs positions are determined by all features. Looking at the abundance profile we see that this is indeed the case.
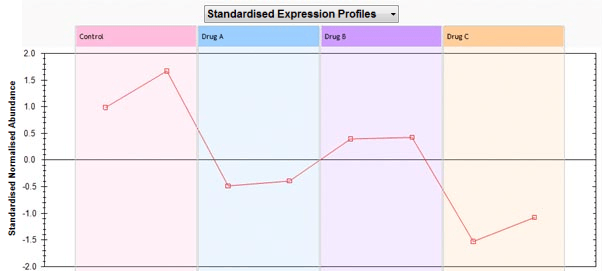
Drug C has a low abundance value for feature 20 while Drug A and Drug B have higher abundance values for the feature. So, in general we can say that features which are close to a run group on the biplot will have higher abundance value in this group than features further away. Also, features that are clustered together on the biplot should have similar abundance profiles and therefore should be clustered together in the Correlation Analysis dendrogram.